相关反馈
主要思想
RF (relevance feedback) 相关反馈的主要思想:在信息检索过程中通过用户交互来提高最终的检索结果。
基本过程
- 用户提交一个简短的查询
- 系统返回初次检索结果
- 用户对部分结果进行标注,将它们标注为相关或不相关
- 系统基于用户的反馈计算出一个更好的查询来表示信息需求
- 利用新查询系统返回新的检索结果
相关示例
例如,用户搜索输入bike之后,可能图库会返回bike的车型、比赛海报、各式各样的车。用户可以将自己期望的结果标注为相关,系统会根据用户的标注信息再检索更多其他结果。

Rocchio算法
假定我们要找到一个最优查询向量$\vec q$,它与相关文档相似度最大,与不相关文档相似度最小。若$C_r$表示相关文档集,$C_{nr}$表示不相关文档集,则最优向量为
$$
\vec q_{opt} = argmax_\vec q [sim(\vec q, C_r)- sim( \vec q, c_{nr})]
$$
若采用余弦相似度计算,
$$
\vec q_{opt} = \frac{1}{|C_r|}\sum_{d_j\in C_r}\vec d_{j}-\frac{1}{|C_{nr}|}\sum_{d_j\in C_{nr}}\vec d_{j}
$$
即,最优化查询向量等于相关文档的质心向量减去不相关文档的质心向量的差。
但检索本身就是要找到相关文档,所有相关文档事先是未知的,所以这个公式没有啥用。
Rocchio算法:假定我们有一个用户查询,并知道部分相关文档和不相关文档的信息,测可以通过如下公式得到修改后的查询向量$\vec q_m$
$$
\vec q_m = \alpha \vec q_0 +\beta\frac{1}{|D_r|}\sum_{d_j\in D_r}\vec d_{j}-\gamma\frac{1}{|D_{nr}|}\sum_{d_j\in D_{nr}}\vec d_{j}
$$
其中,$\vec q_0$是原始查询向量,$D_r,D_{nr}$是用户标记的相关和不相关文档集合,$\alpha,\beta,\gamma$是上述三个向量权重系数。
理解:修改后的新查询从$\vec q_0$开始,向着相关文档质心向量靠近一段距离,又同时离不相关文档远离一段距离。一般来说,正反馈比负反馈更有价值,因为有的时候用户标注的不相关文档与相关文档具有很高的相似性,用户只是因为少数几个词或者内容不够完整的原因将其标注为不相关。很多IR系统中,$\alpha=1,\beta=0.75,\gamma=0.15$。存在一种做法是,只取检索系统返回结果排名最高的标记为不相关文档。
相关反馈的作用时机
相关反馈的成功依赖于某些假设:
用户必须要有足够的知识来建立一个不错的初始查询,该查询至少要在某种程度上接近需求文档。但是在某些情况下,仅仅使用相关反馈技术并不足以解决问题:
- 拼写错误
- 跨语言IR
- 用户的词汇表和文档集的词汇表不匹配
相关反馈方法要求相关文档之间非常相似。如果相关文档包括多个不同子类,即它们在向量空间中可以聚成多个簇,那么Rocchio方法效果会不太好。这种问题可能发生的情形如下:
- 文档子集之间使用不同的词汇表
- 某个查询的答案集合本身就需要不同累的文档来组成
- 通用概念的例子,它通常以多个具体概念的或关系来出现
伪相关反馈与间接相关反馈
伪相关反馈,pseudo relevance提供一种自动局部分析方法。它将相关反馈的人工操作部分自动化,因此用户不需要额外的交互就可以获得检索性能的提升。该方法首先进行正常的检索过程,返回最相关的文档构成初始集,然后假设排名最靠前的k篇文档是相关的,最后在此假设上像以往一样进行相关反馈。
间接相关反馈,也称为隐式相关反馈。隐式反馈不如显式反馈可靠,但是会比没有任何用户判定信息的伪相关反馈更有用。例如,在web中,对于某文档如果用户浏览次数越多,则它的排名越高。这种页面点击率数据的收集实际上是点击流挖掘(clickstream mining)的一种形式。
查询重构
扩展查询的全局方法:
- 简单辅助用户进行查询扩展
- 采用人工词典的方法
- 自动构建词典的方法
查询扩展
在查询扩展(query expansion)中,用户会对查询词或短语给出额外的输入信息。
最普遍的查询扩展方法是通过某种形式的同义词词典进行全局分析。
用于查询扩展的同义词词典构建方法如下:
- 使用人工编辑的一部受控词汇表。例如UMLS系统。
- 使用人工编纂的同义词词典。
- 使用自动构建的同义词词典。
- 基于查询日志挖掘进行查询重构。
基于词典的查询扩展方法的有点是不需要用户输入任何信息。
同义词词典自动构建
两种实现方法:
- 简单的使用词共现信息。(更健壮)
- 采用浅层语法分析器来分析文本,得到词汇之间的语法关系或语法依存性。(更精确)
XML检索
将IR与关系型数据库比较,IR系统一直从无结构的文本中检索信息,这里的无结构信息指的是不带标记的原始文本。
但是,很多包含文本的结构化数据源最好通过结构化文档而不是关系型数据来建模。基于结构化文档的搜索称为结构化检索。
XML基本概念
一篇XML文档是一个有序的带标签树,树上的每个节点都是一个XML元素(XML element),它由起始标签(tag)和结束标签来界定。
<play>
<author>Shakespeare</author>
<title>Macbeth</title>
<act number="I">
<scene number="vii">
<title>Macbeth’s castle</title>
<verse>Will I with wine and wassail ...</verse>
</scene>
</act>
</play>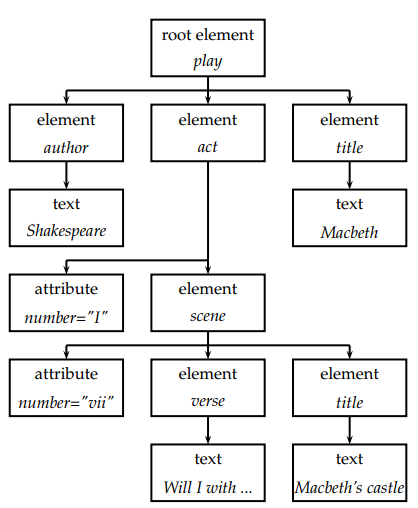
树的叶节点包含了一些文本,比如Shakespeare, Macbeth等。而树的内部节点包含对文档结构信息,如title, act等。
访问和处理XML文档标准是XML DOM(文档对象模型)
XPath是XML文档集中的路径表达式描述标准,路径也称为XML上下文。
- XPath表达式中的node表示选择满足该表达式的所有节点
- 路径上前后元素间用斜杠“\”来分割
- 双斜杠表示路径中可以插入任意多个元素。
- 路径若以斜杠开始则表示该路径起始于根元素
- 为便于表示,允许路径上的最后的元素是词汇表中的一个词项,并利用“#”号将其与前面的路径分隔开来。
如果去掉XML文档的属性,也就是将XML文档中所有属性节点全部去掉,可以得到仅包含元素这一种类型节点的树结构。用同样的方法也可以将查询表示成树。
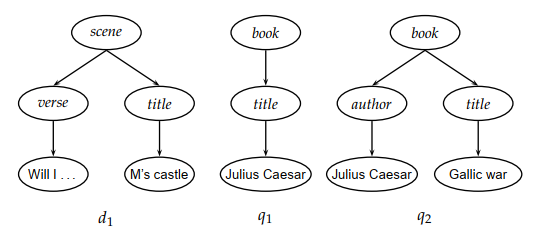
挑战性问题
挑战一:用户希望返回文档的一部分(XML元素),而不像非结构化检索一样返回整个文档
检索策略:返回包含信息需求的最小单位。但确定查询应答的正确层次是非常困难的。
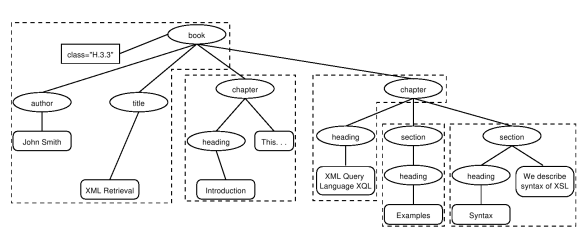
方法一:将节点分组,形成多个互不重叠的伪文档。
缺点:这些伪文档内容不连贯,对用户而言没有什么意义。
方法二:“两步走”,使用最大的一个元素作为索引单位。然后对结果进行后处理。例如,对于上面莎士比亚剧本的例子,查询”Macbeth’s castle”,先以play为索引,找到Macbeth这个剧本,再在这个剧本下找到第一幕第7场可能是匹配最佳的子元素。
缺点:对很多查询来说,分两步走的做法不能返回最优匹配子结构,因为整本书与查询的相关性不能代表子元素与查询的相关性。
方法三:限制最少的方法是对所有元素建立索引。
缺点:
- 很多XML元素不是有意义的检索结果
- 对所有元素建立索引意味着高度的冗杂性
挑战二:由于元素之间嵌套关系的存在,在结果排序中计算词频统计信息,必须要区分词项的不同上下文
方法:为XML每个上下文-词项对计算idf值
缺点:会导致数据稀疏问题,很多上下文-词项对出现过少导致文档频率估计可靠性不足
折中方案:在区分上下文时只考虑词项的父节点x,而不考虑从根节点到x路径上其他部分
基于向量空间模型的XML检索
一种实现方法是,对向量空间中的每一维都同时考虑单词及其在XML树中的位置信息。
- 首先考虑每个文本节点并将它们分裂成多个节点,每个节点对应一个词
- 将向量空间每一维定义为文档的词汇化子树,这些子树至少包含词汇表中的一个词项
- 将查询和文档表示成词汇化子树空间上的向量,并进行计算
由于每个词汇话子树看成一维,整个空间维数非常大,一个折中的方法是对所有的最终以单个词项结束的路径建立索引,即对所有XML上下文-词项对建立索引。
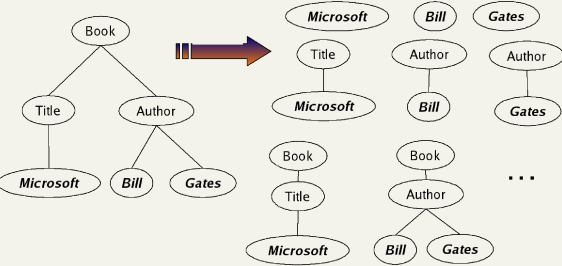
这种XML上下文-词项对被称为结构化词项,记为<c,t>,c表示XML上下文,t是词项。
对于用户的查询,我们希望优先考虑与查询结构相匹配且中间节点数量较少的文档,一个简单的度量查询路径$c_q$与文档路径$c_d$相似度的指标是上下文相似度$C_R$,
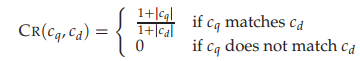
最终的文档得分计算:
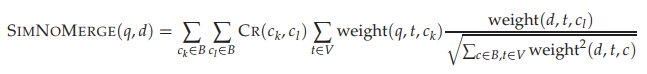


XML检索的评价
部件覆盖度(component coverage)评价的是返回元素在结构上是否正确,也就是说,其在树中的层次既不太高也不太低。部件覆盖度分为以下四种情况:
- 精确覆盖(E):所需求的信息是部件的主要主题,并且该部件是一个有意义的信息单位。
- 覆盖度太小(S):所需求的信息是部件的主要主题,但是该部件不是一个有意义(自包含)的信息单位。
- 覆盖度太大(L):所需求的信息在部件中,但不是主要主题。
- 无覆盖(N):所需求的信息不是部件的主题。
主题相关性有四个层次:强相关(3)、较相关(2)、弱相关(1)和不相关(0)。
每个部件在覆盖度和主题相关性两个方面都要进行判断,然后将判断结果组合成一个数字-字母编码。
相关度-覆盖度组合量化方法:


