计算机并行技术可以分为:
- 指令级并行(ILP):在单个处理器上同时执行多条指令的能力
- 线程级并行(TLP):任务被组织成多个线程,在多线程环境中同时执行多个线程的能力
- 数据级并行(DLP):同时处理多个数据元素的能力
ILP在流水线一章已经介绍,本章主要介绍TLP和DLP。
线程级并行
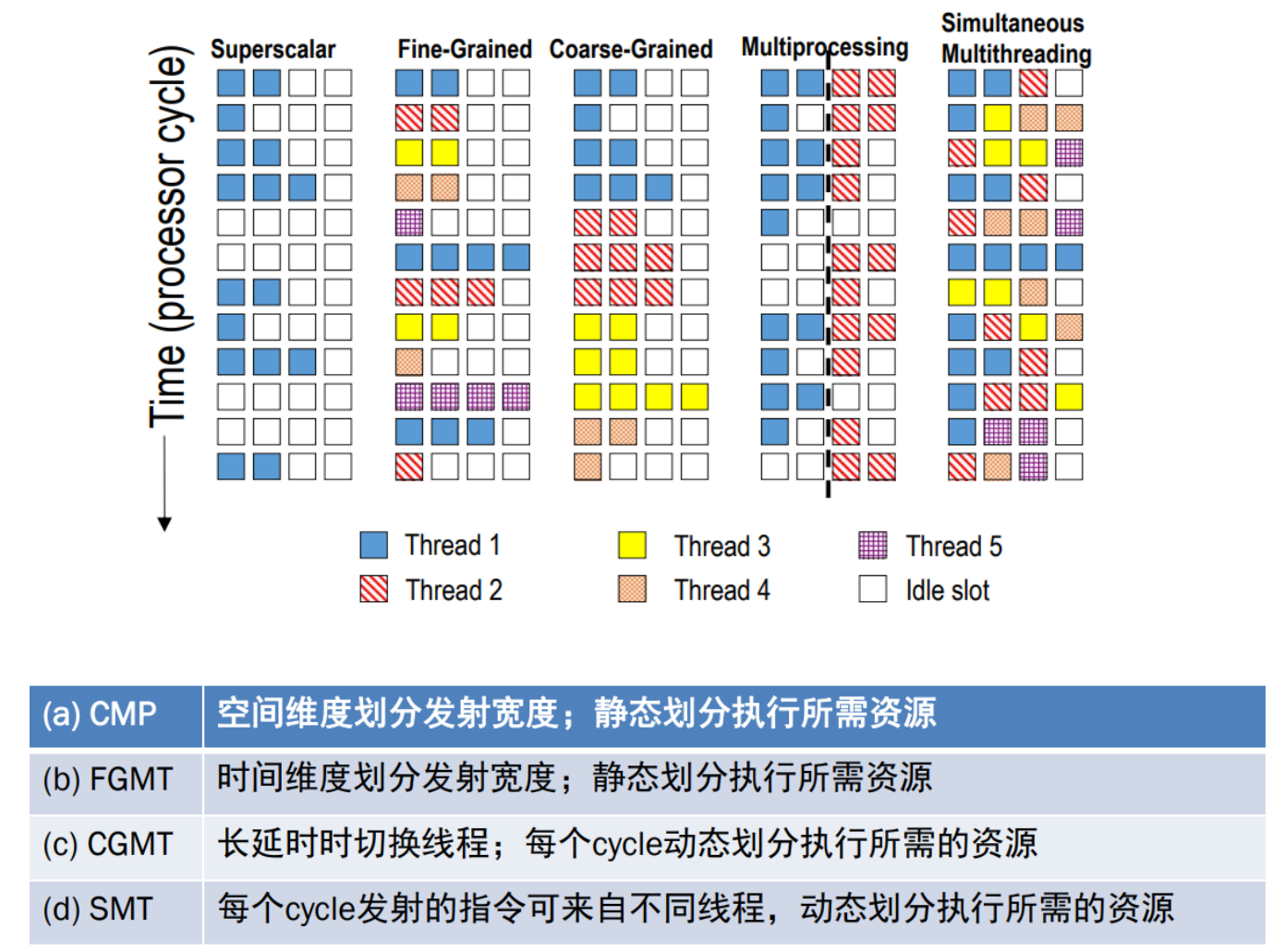
Chip Multiprocessing(CMP)策略每个处理器执行一个线程,单个处理器核无法执行不同线程。这样做从单个处理核上看,是没有减少时间和空间维度的浪费。
Coarsed-Grained MT策略中,当一个线程存在较长的时间延时时,会切换另一线程。缺点是无法避免小的停顿。
Fine-Grained MT策略则频率高,周期短地切换线程,多个线程的指令交叉执行。缺点是牺牲了单线程的执行性能,换取多线程吞吐量的提升。
Simultaneous Multithreading 同步多线程策略使用OoO Superscalar细粒度控制技术在相同时钟周期运行了多个线程的指令,以更好利用系统资源。
数据级并行
Flynn将计算机分为四类:
- SISD:单条指令操作一条数据,例如之前介绍的简单流水线
- MISD:多条指令操作一条数据,很少
- MIMD:多条指令操作多条数据,例如VLIW
- SIMD:单条指令操作多条数据, 例如Vector Processor,GPU
数据级并行就是指的SIMD,SIMD可以分为array processor和vector processor,array processor由多种ALU组成,成本更高,同一个时间可以有多个数据执行相同操作,vector processor每种硬件单元只有一个,同一个时间不同数据无法执行相同操作。
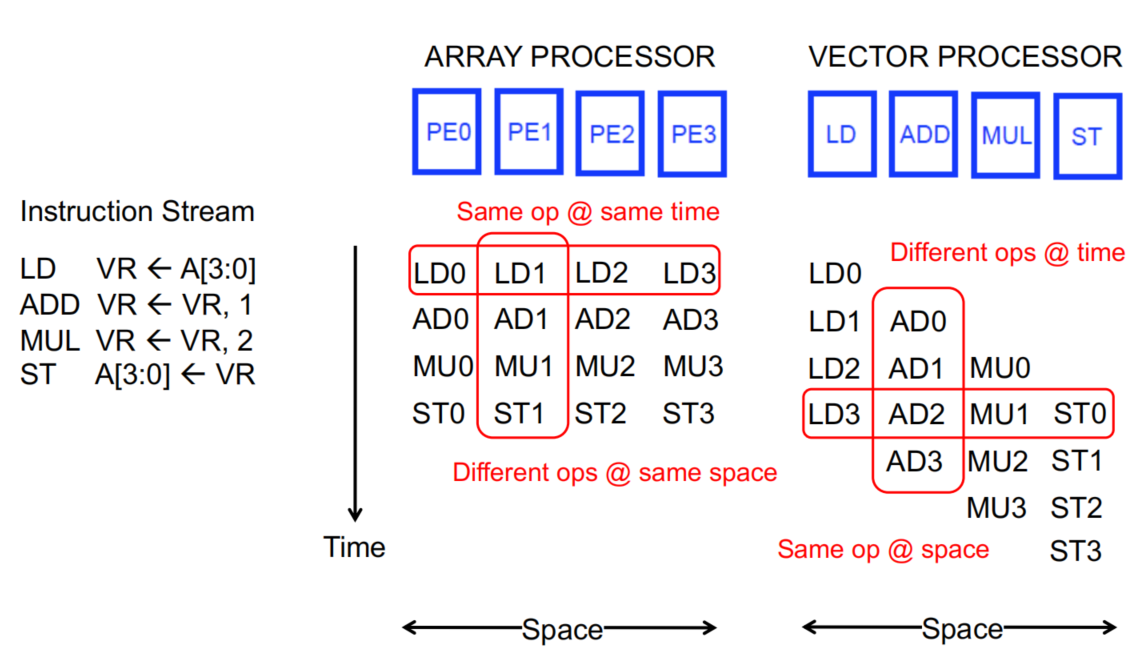
加载数据
SIMD需要同时执行多条数据,首先需要解决的问题是如何load这些数据进入运算单元。如果逐一访问数据读取,对于常常需要load/store大量数据的SIMD而言,memory会成为瓶颈,于是需要memory bank加速这一过程。
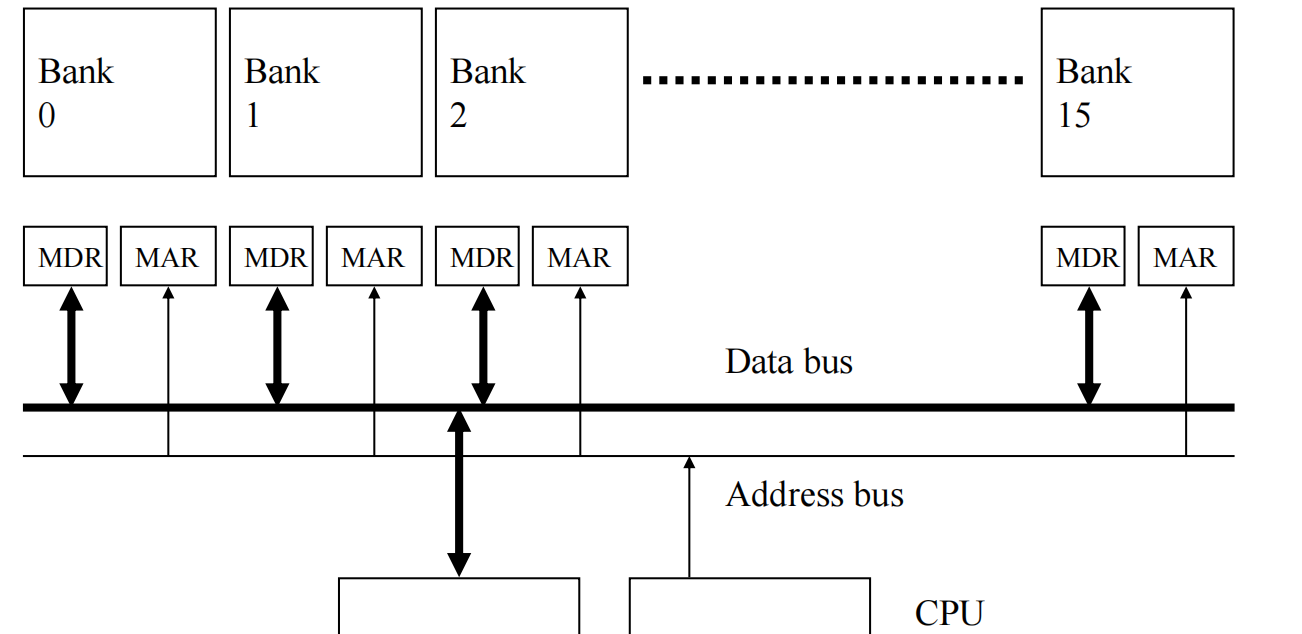
有了memory bank,数据的访问可以pipelined,假设第1个数据放在Bank0,第二个数据放在Bank1,依次类推,且获取1个数据需要11个周期。第一个周期将地址1发给bank0,第二个周期将地址2发给Bank1,第3个周期将地址3发给Bank2,以此类推…到第11个周期时,Bank0的数据就返回了,第12个周期Bank1的数据返回,之后每个周期都有数据返回。
如果数据的stride为2,即第1个数据放在Bank0,第2个数据放在Bank2,第3个数据放在Bank4,依次类推。那么第8个周期需要再次访问Bank0时,Bank0会处于繁忙状态,需要再等4个周期才能访问。所以stride最好与Bank互质。
来看一个例子:
For I = 0 to 49
C[i] = (A[i] + B[i]) / 2翻译成汇编语言如下:(每天指令后面标注了需要的周期数)
MOVI R0 = 50 1
MOVA R1 = A 1
MOVA R2 = B 1
MOVA R3 = C 1
X: LD R4 = MEM[R1++] 11 ;autoincrement addressing
LD R5 = MEM[R2++] 11
ADD R6 = R4 + R5 4
SHFR R7 = R6 >> 1 1
ST MEM[R3++] = R7 11
DECBNZ R0, X 2 ;decrement and branch if NZ假如只有1个Memory Bank,两条LD指令都需要执行11个周期,总执行周期为4+50*40=2004。
假如有2个memory且A,B存在不同bank上,第11个周期读取A后,第12个周期立马能得到B,总执行周期为4+50*30=1504。
如果使用向量指令,汇编代码为:
MOVI VLEN = 50 1
MOVI VSTR = 1 1
VLD V0 = A 11 + VLEN – 1
VLD V1 = B 11 + VLEN – 1
VADD V2 = V0 + V1 4 + VLEN – 1
VSHFR V3 = V2 >> 1 1 + VLEN – 1
VST C = V3 11 + VLEN – 1这里的VLEN表示数据执行长度,例如SIMD一次最多能够执行64条数据,但这里不足64条数据,所以需要VLEN修改数据长度,VSTR表示不同数据的stride,用于向memory bank寻址。
假如没有vector chaining(类似于流水线中的data forwarding),且每个bank只有1个port,总共有16个bank,那么两次vector load都需要11+50-1=60个cycles,总时间周期为1+1+60+60+50+53+60=285个周期。
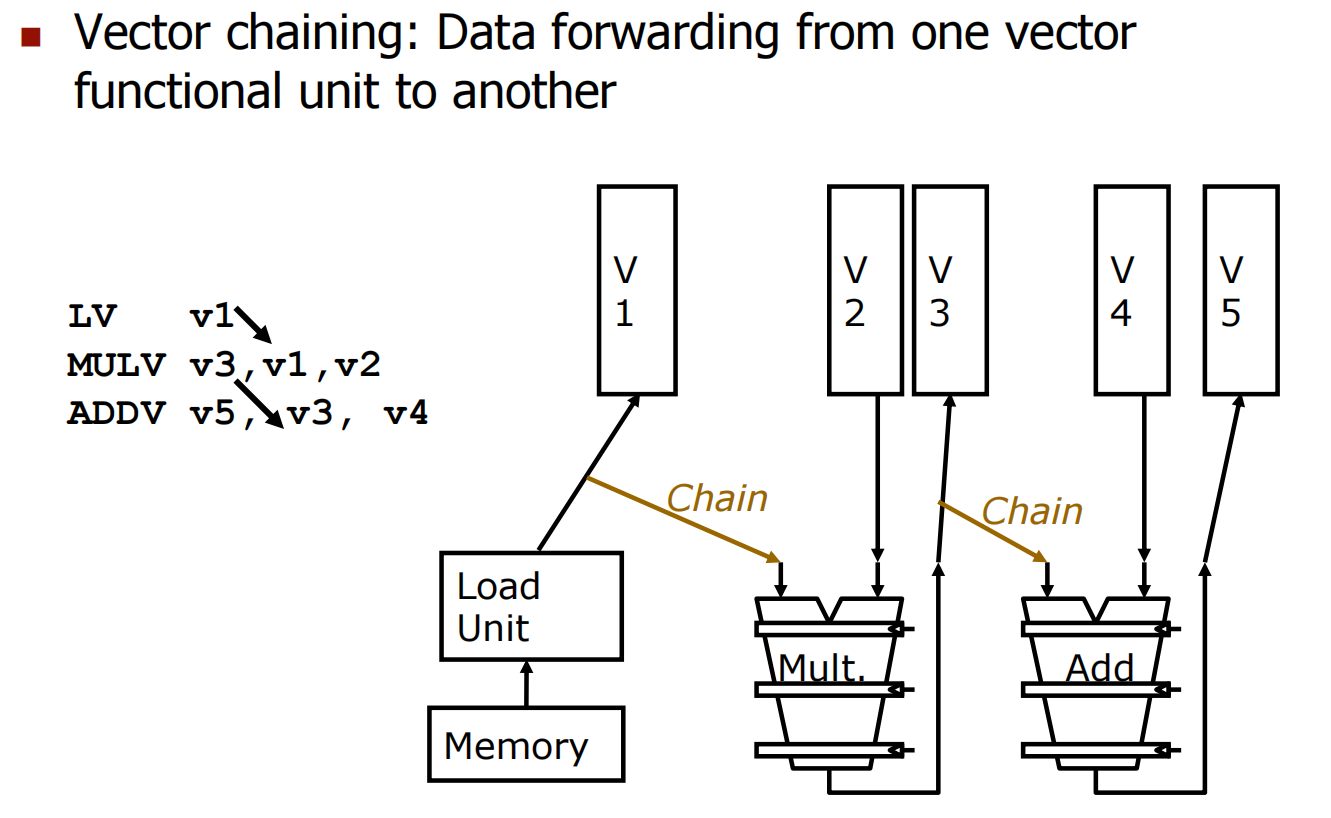
如果使用vector chaining,每条指令不需要等到前一条指令执行完再启动,这时只需要182 cycles,执行流程如下图所示:
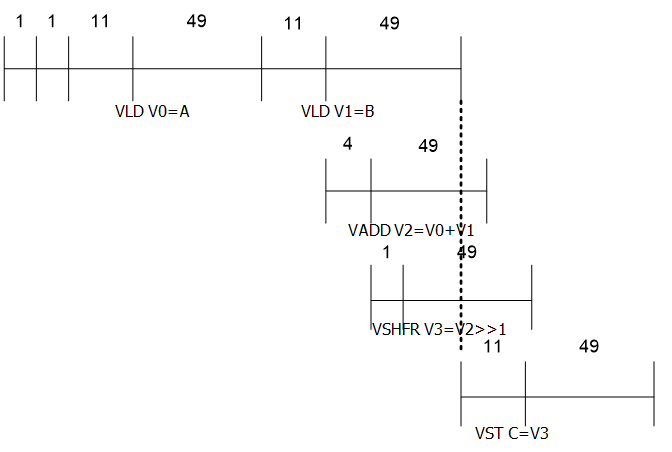
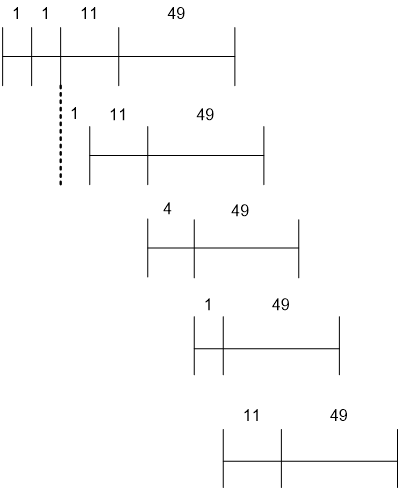
上图中LD指令和ST指令仍然无法并行,这是因为上面我们假设每个bank只有1个port,所以无法同时执行多个内存操作,假设每个bank有两个load ports和1个store port,可以进一步缩短到79个周期。
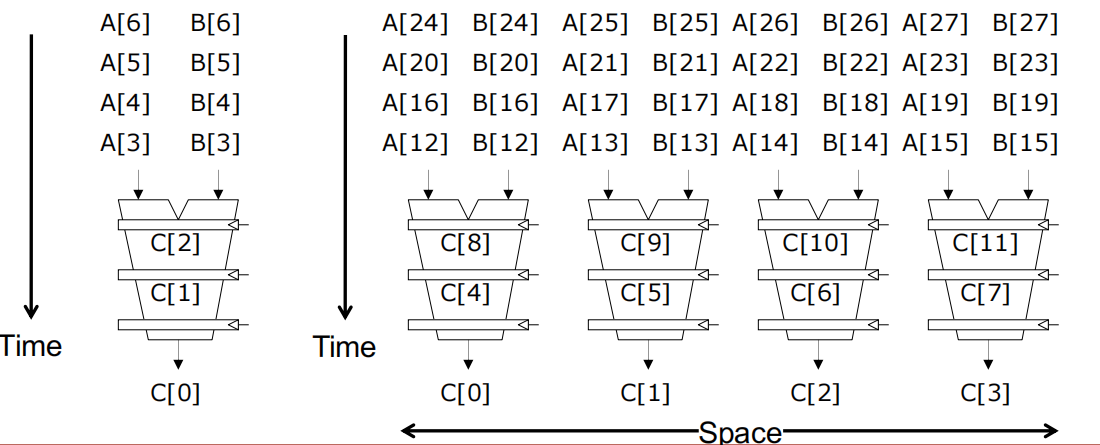
以上是一次处理50个数据的情况,假如SIMD机器只有64个VREGs,但是要处理527条数据,那么就需要分块处理,分为8次VLEN=64的迭代和1次VLEN=15的迭代。这种方式也被称为Strip mining。
刚才都是讨论数据是规则存放,可以通过stride进行寻址,如果数据是不规则存放,则需要通过Gather/Scatter Operations先获取数据地址,再根据基址间接寻址。

执行指令
SIMD的执行相对简单,因为不需要考虑不同执行之间冲突关系,顺序执行即可。但是需要注意的是分支指令的处理,为了保证并行度,分支指令通过一个掩码VMASK进行处理。
for (i = 0; i < 64; ++i)
if (a[i] >= b[i])
c[i] = a[i]
else
c[i] = b[i]| A | B | VMASK |
|---|---|---|
| 1 | 2 | 0 |
| 2 | 2 | 1 |
| -5 | -4 | 0 |
需要注意的是,数据执行分配在固定的车道上,即使另一条数据被掩码了,也不能更换车道执行。
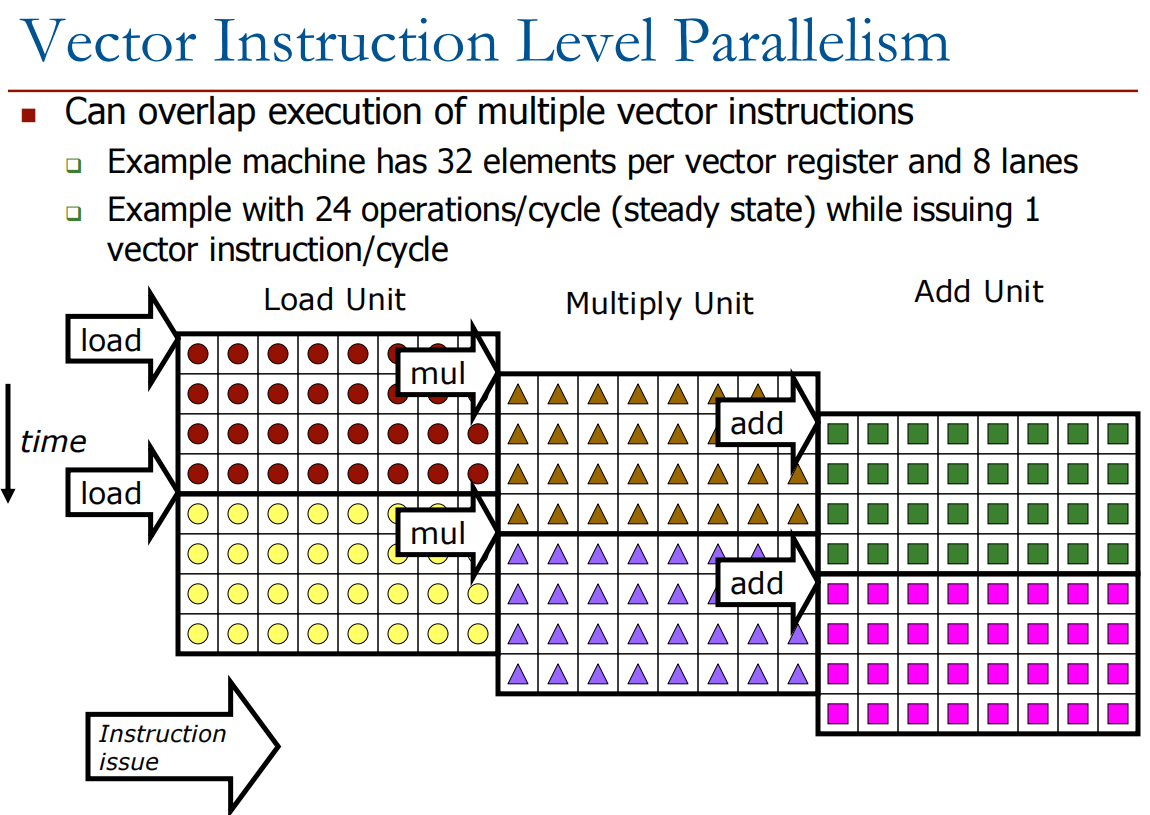
SIMT
以上提到的数据并行,是通过vector instruction驱动的,SIMT则是另一种思路:single instruction multiple thread,将一组执行相同指令的线程并行执行,GPU就是采用这种方式,在GPU中这些并行执行的线程被称之为Warp。
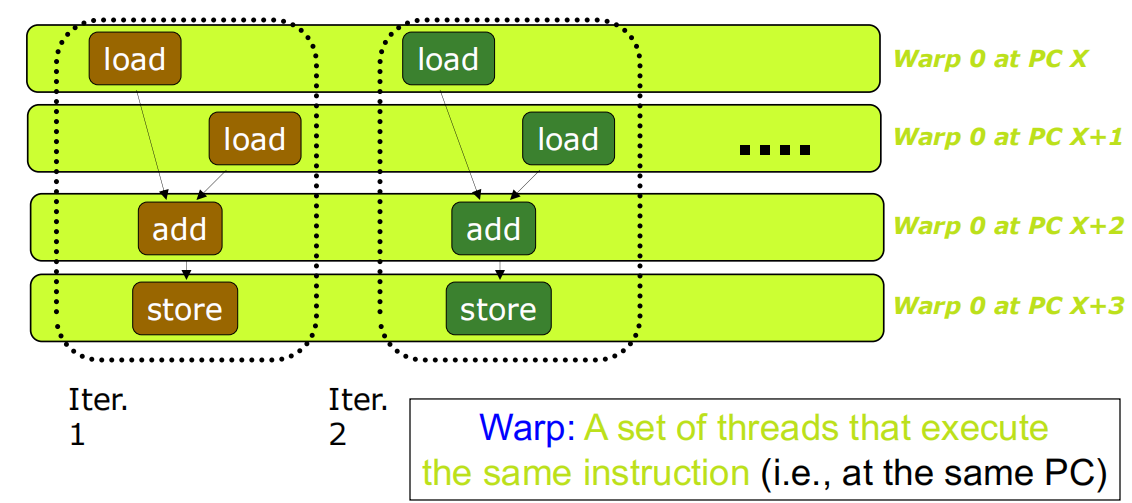
大量相同指令会被GPU分为多个warps,warps不向GPU编程者暴露,由内部硬件组织管理。GPU中多个线程(Thread)构成一个多线程块(Block),大量Block块构成网格(Grid)。Warp是线程调度的基本单位。
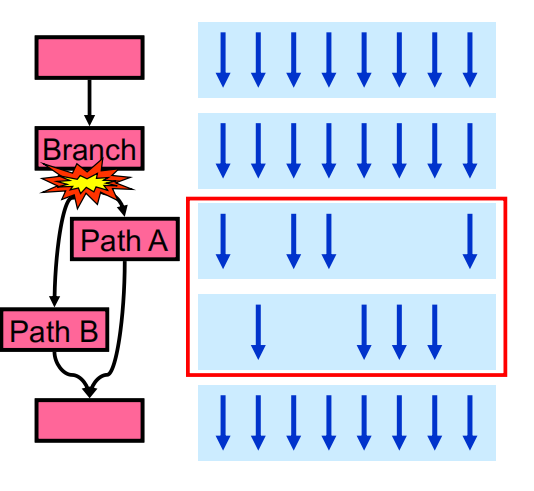
在面对分支指令时,warp会根据分支方向分成不同路径执行。
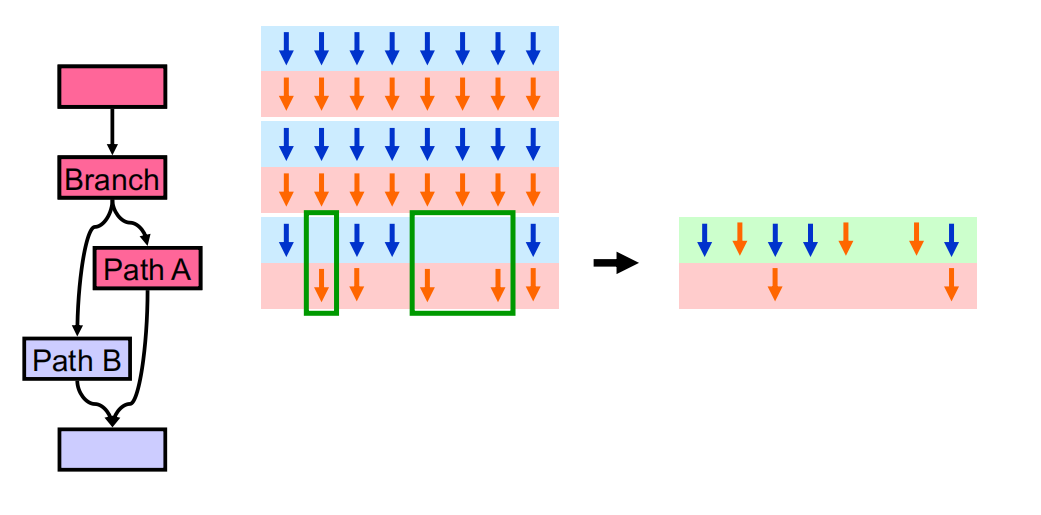
当同一个block中不同的warp执行相同的指令,可以动态进行合并,从而提高GPU效率。
小结
本章简略介绍了线程级并行和数据级并行,由于内容过多、时间有限,只能对这两部分做一个简单的介绍。线程级并行, 主要有CMP、粗粒度、细粒度、同步多线程四种调度策略。数据级并行主要介绍了SIMD和SIMT两种方式,前者是通过vector instruction进行调度,后者是GPU的方式,将相同指令的多个线程同时执行。这两部分还有非常多可挖掘的点,尤其是GPU的结构、执行、编程细节本文都没有深入展开,后续有时间可以将GPU编程进行扩展。

