GPU简介
近年来,随着深度学习的快速发展,GPU在计算领域扮演着越来越重要的角色,已经成为了人工智能和机器学习领域的关键组件。进入大模型时代,模型近乎恐怖的算力需求需要高性能的计算资源来完成,而 GPU 具有大量的计算核心和高速的显存,使得它能够高效地处理这些计算任务,从而成为了大模型训练和推理不可缺少的工具。
插播一条新闻:
Meta engineers trained Llama 3 on computer clusters packing 24,576 NVIDIA H100 Tensor Core GPUs, linked with RoCE and NVIDIA Quantum-2 InfiniBand networks.
To further advance the state of the art in generative AI, Meta recently described plans to scale its infrastructure to 350,000 H100 GPUs.
–From Wide Open: NVIDIA Accelerates Inference on Meta Llama 3 | NVIDIA Blog
为什么深度学习需要使用GPU?
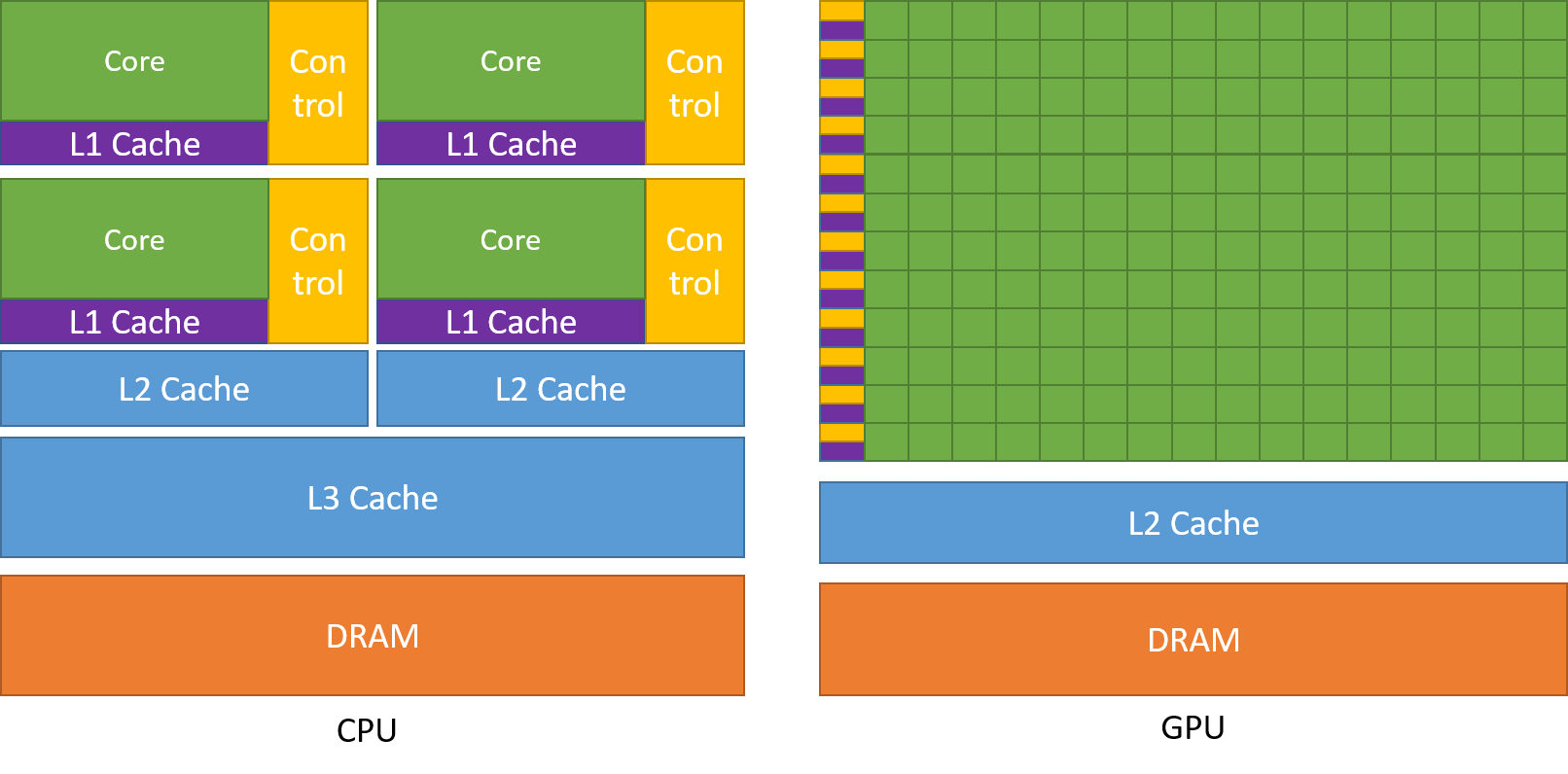
这个答案可以从下面这张图中看出端倪:
- 绿色部分是计算单元,GPU有着更多的计算核心,计算能力更强。
- 黄色部分是控制单元,CPU中有大量的控制单元,现代CPU的晶体管越来越复杂,除了“计算”,还要实现乱序执行、分支预测、高速缓存等功能;而GPU中控制单元很少,是专门用于并行计算
深度学习中存在大量矩阵运算都是并行执行的,GPU非常适合对这类高度并行性的任务进行计算加速
GPU架构
Nvdia每几年都会提出新的GPU架构,并且都是以著名的物理学家对架构进行命名。但这些更新主要是增加硬件单元的数量,组成结构基本没有变化。
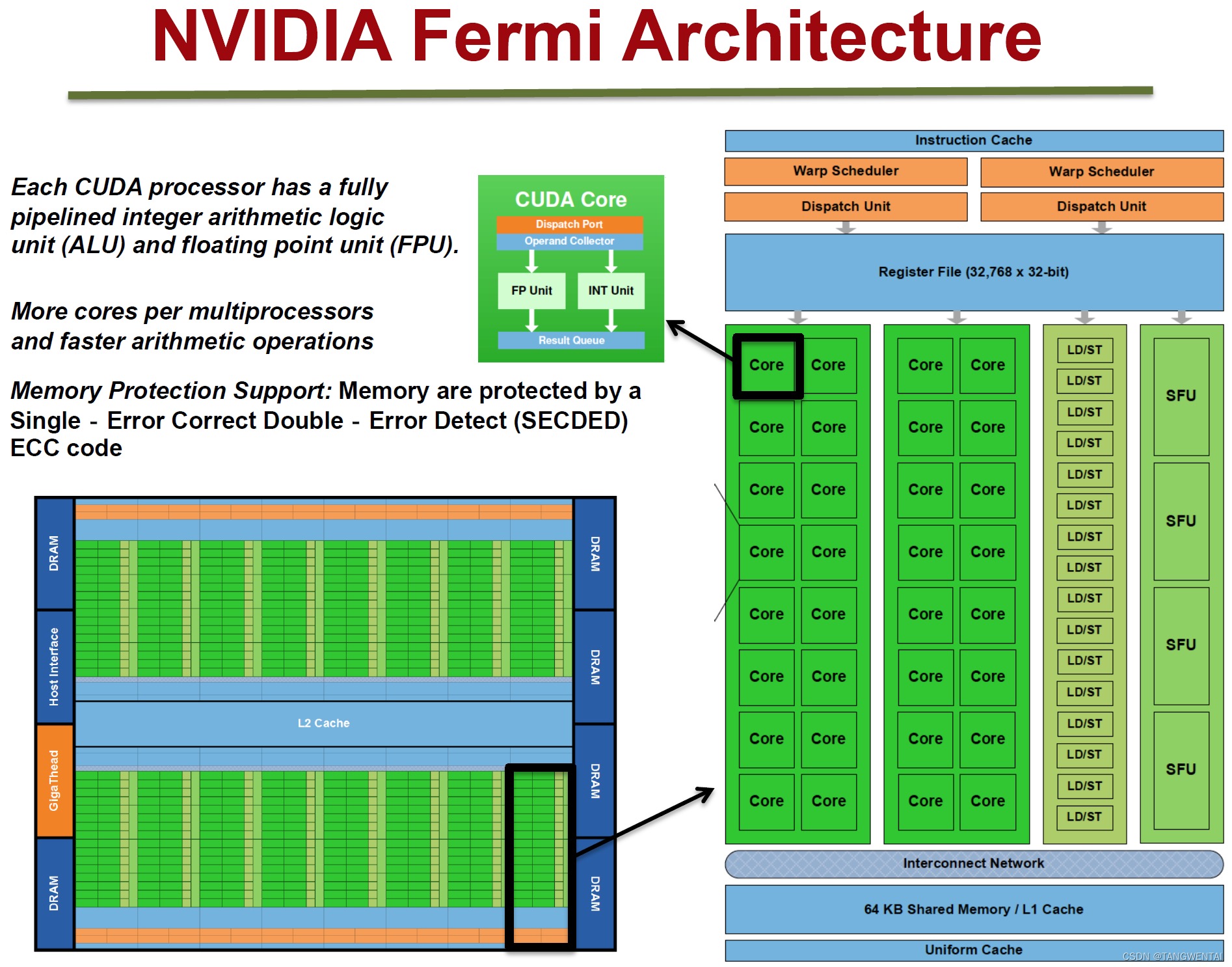
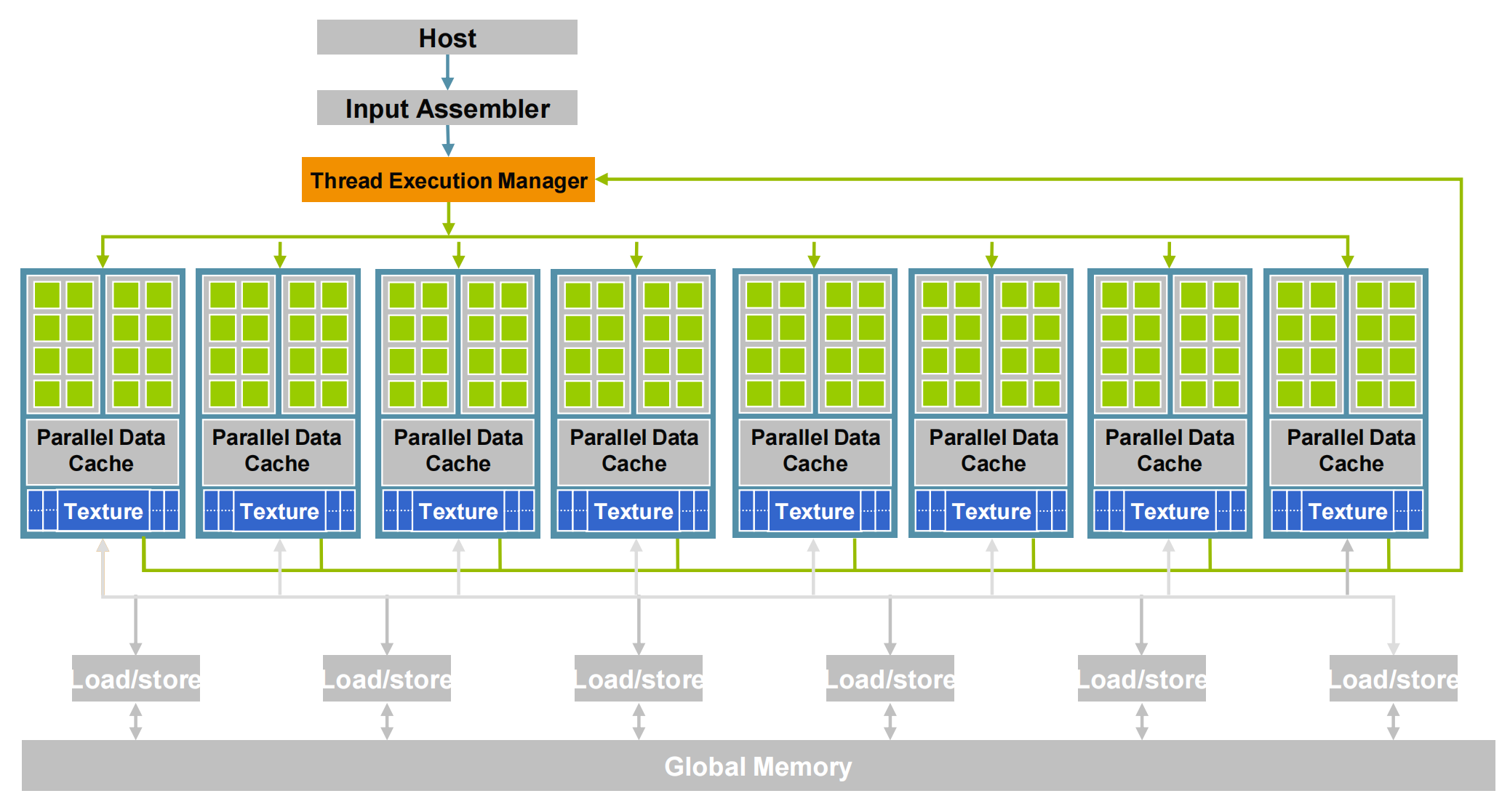
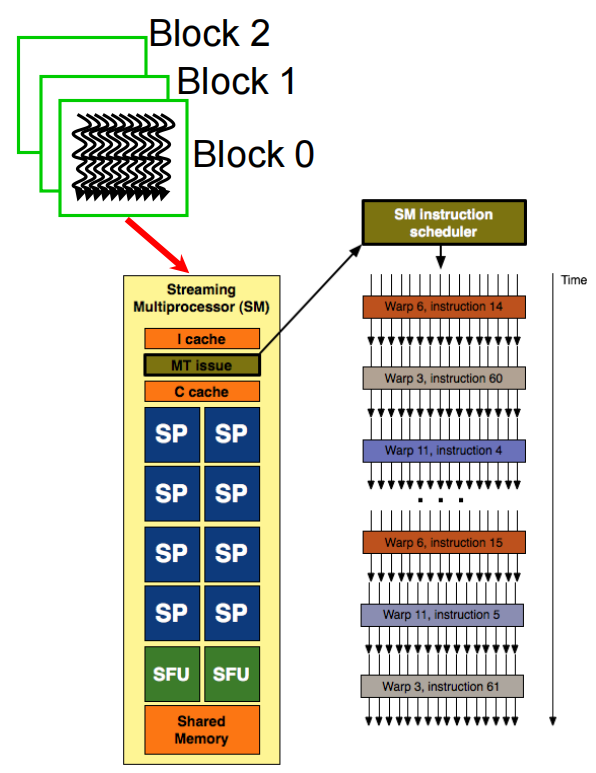
下图展示了GPU的Fermi 架构(其他架构大体结构基本相同,主要是硬件数量的变化)。
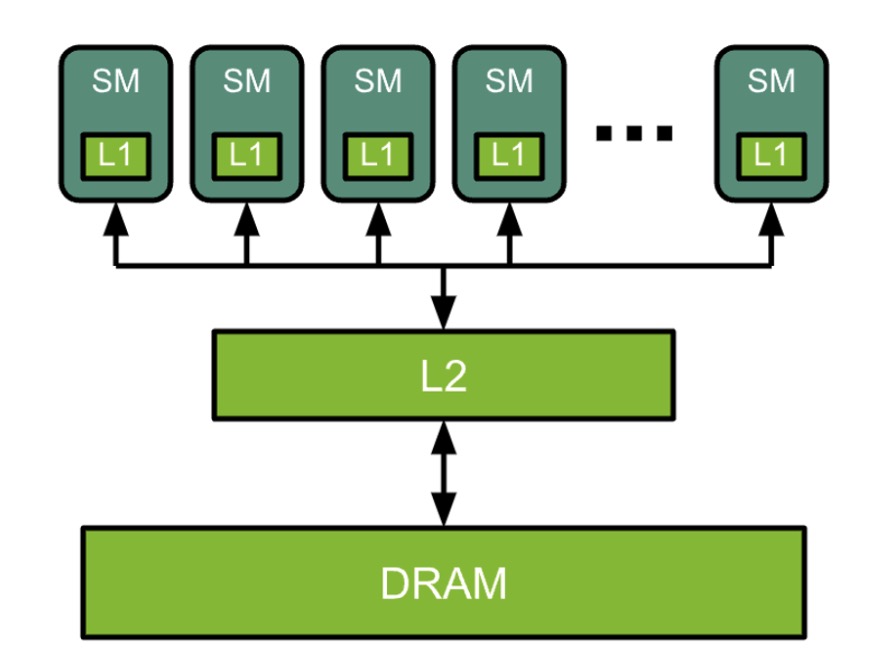
一块GPU上存在多个Streaming Multiprocessor(SM),每个SM上有很多个计算核心(Core)、线程调度器(Warp Scheduler)、Shared Memory(共享内存)、SFU(特殊运算单元,如sin、cos)、Register File(寄存器组)。除了每个SM上的Share Memory,所有SM会共享Global Memory。
可以看到GPU这样的硬件结构专为大规模并行和高吞吐量而设计的,下面我们结合这种硬件结构具体讨论GPU是如何进行并行计算。
Flynn将计算设备分为四类:
- SISD:单条指令操作一条数据,例如之前介绍的简单流水线
- MISD:多条指令操作一条数据,很少
- MIMD:多条指令操作多条数据,例如VLIW
- SIMD:单条指令操作多条数据, 例如Vector Processor,GPU
GPU则是SIMD中的一种,也就是说它一条指令可以操作多条数据,更具体地说,GPU采用的是一种SIMT(Single-Instruction, Multiple-Thread)的架构,也就是一条指令可以执行多个线程。在程序运行时,GPU会同时执行大量相同指令的线程。而这些线程首先会通过一个调度器,调度到闲置的SM上,再由SM内部的Warp Scheduler调度到Core上进行计算。目前,我们还没有介绍CUDA中的概念,下一节我们将结合CUDA编程模型中的概念再一次讲述整个调度过程。
CUDA简介
GeForce 256是英伟达1999年开发的第一个GPU,最初只用作显示器上渲染高端图形,只用于像素计算。在早期,OpenGL和DirectX等图形API是与GPU唯一的交互方式。后来,人们意识到GPU除了用于渲染图形图像外,还可以做其他的数学计算,而OpenGL和DirectX等图形API的交互方式比较复杂,不利于程序员设计GPU计算,这促成了CUDA编程框架的开发,它提供了一种与GPU交互的简单而高效的方式。
CUDA环境准备
在开启cuda编程之前,首先需要检查开发环境是否具备必要的条件:
- Nvidia的GPU
- Nvidia的显卡驱动
- 标准的C编译器
- CUDA开发工具
由于我直接用了建立好的环境,建立环境的过程在此博客就不展开,可以参考以下网址:
CUDA 编程指南
CUDA 开发环境
为各种 NVIDIA 架构匹配 CUDA arch 和 CUDA gencode
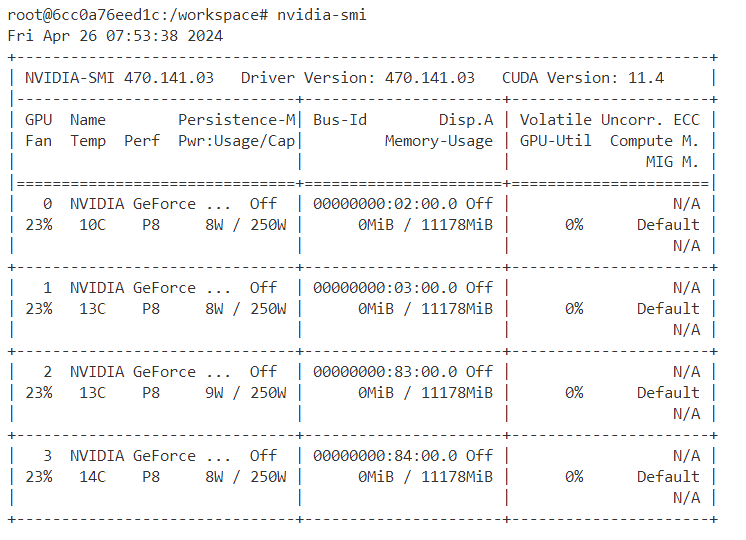
建立好CUDA开发环境之后,可以通过以下命令进行检查:
nvidia-smi应该看到:
nvcc --version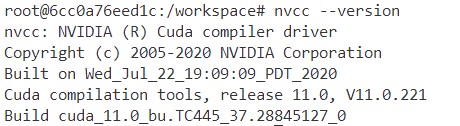
CUDA编程模型
在开始CUDA编程之前,首先要了解CUDA中涉及到的概念:“grid”、“block”、“thread”。
thread:一个CUDA的并行程序会被以许多个thread来执行
block: 多个线程组成一个线程块(Block),同一个block的线程会被调度到同一个SM上,即同一个block的thread可以进行同步并可用SM上的share memory通信,不同block的thread无法通信。
grid: CUDA的一个函数叫做一个kernel,一个kernel会发起大量执行相同指令的线程
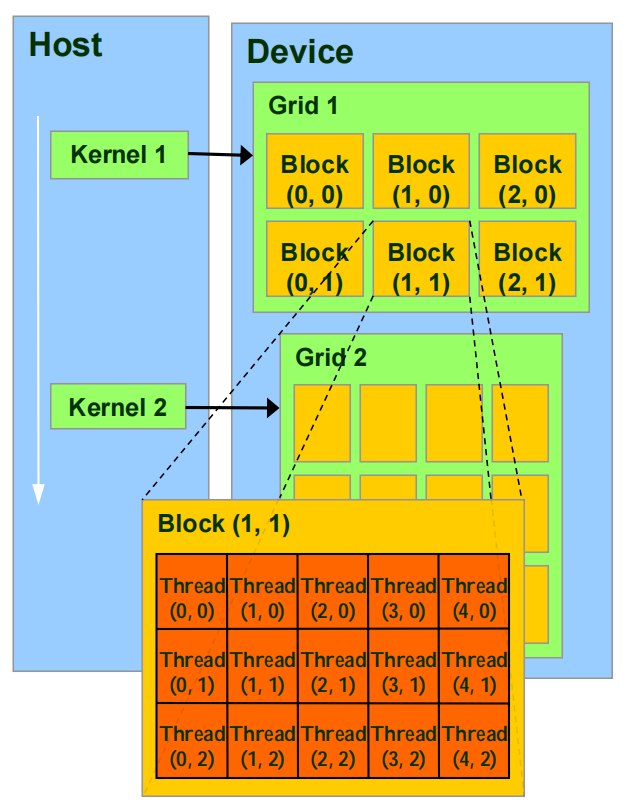
这三个概念是CUDA编程中最核心的,只要知道这些,我们就已经可以写cuda代码了,那些SM、Share Memory等硬件概念不知道都没有关系,但了解硬件结构可以帮助我们更好地对cuda代码深度优化。
既然知道“grid”、“block”、“thread”这些概念就可以写cuda程序了,那我们就尝试编写一个cuda程序hello-gpu.cu,让GPU输出“Hello World!”。
#include <stdio.h>
void helloCPU()
{
printf("Hello World!\n");
}
__global__ void helloGPU()
{
printf("Hello World! --From GPU\n");
}
int main()
{
helloCPU();
helloGPU<<<1, 1>>>();
cudaDeviceSynchronize();
}可以看到cuda程序和普通的c语言非常相似,下面我们讲讲不一样的地方:
__global__:定义这是一个cuda的kernel函数,从主机host发起并在设备device上执行。<<<1, 1>>>:定义block和threads,这里表示发起1个block,每个block里有1个线程cudaDeviceSynchronize:与许多 C/C++ 代码不同,核函数启动方式为异步:CPU 代码将继续执行而无需等待核函数完成启动。调用 CUDA 运行时提供的函数cudaDeviceSynchronize将导致主机 (CPU) 代码暂作等待,直至设备 (GPU) 代码执行完成,才能在 CPU 上恢复执行。
写好cuda代码后,我们可以使用nvcc对代码进行编译与执行:
nvcc -arch=sm_61 -o hello-gpu hello-gpu.cu -runnvcc是使用nvcc编译器的命令行命令。- 将
xxx.cu作为文件传递以进行编译。 o标志用于指定编译程序的输出文件。arch标志表示该文件必须编译为哪个架构类型。本示例中,sm_61将用于专门针对本实验运行的 NVIDIA GeForce GTX 1080 Ti 进行编译,但有意深究的用户可以参阅有关arch标志、虚拟架构特性 和 GPU特性 的文档。- 为方便起见,提供
run标志将执行已成功编译的二进制文件。
从上面的程序,我们可以知道GPU的工作任务是由CPU触发的,GPU自身是无法独立工作的。cuda程序整体的工作流程是CPU将需要执行的任务异步地交给GPU,再由GPU进行调度,最后再将计算结果同步给CPU。
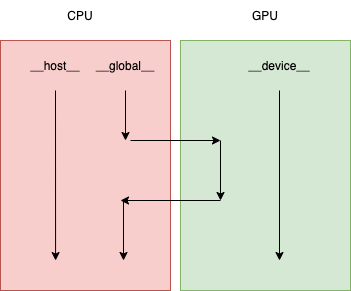
假设我们想要GPU发送66个”Hello World”,我们可以简单地修改blocks和ThreadsPerBlock的数量,即可实现这项功能:
#include <stdio.h>
void helloCPU()
{
printf("Hello World!\n");
}
__global__ void helloGPU()
{
printf("Hello World! --From GPU\n");
}
int main()
{
helloCPU();
helloGPU<<<6, 11>>>();
cudaDeviceSynchronize();
}以上代码则发起了6个block,每个block里有11个线程。当然,我们也可以改成helloGPU<<<1, 66>>>();,发起了一个block,这个block里有66个线程。
Warp
具体怎么设置发起blocks和ThreadsPerBlock完全由程序员自己设置,而发起后这些block和线程在GPU中如何调度则由GPU内部硬件控制,不被程序员所操作。但为了更合理地设置blocks和ThreadsPerBlock,我们还是需要了解GPU中的调度策略。
首先是blocks的调度,同一个blocks会被调度到同一个SM,不同的blocks不保证在同一SM,为了更好地进行调度,blocks数可以设置为GPU中SM的整数倍。由于SM上的计算单元是有限的,同一个blocks中的threads会被划分成多个warp,一个warp才是GPU调度与执行的基本单元。一般来说,一个warp是32个线程,所以ThreadsPerBlock一般会设置成32的整数倍,可以让资源利用率更高。
了解了GPU中的调度逻辑,编写cuda程序时我们就可以根据手中的GPU硬件配置,合理地设置blocks和ThreadsPerBlock这两个参数。当前GPU硬件配置有很多内容,这会让我们目不暇接,在初学CUDA编程中应该关注到的是GPU上SM数量,warp size,每个block的最大线程数,每个SM最大block数。下面我们通过这段代码将GPU硬件信息打印出来。
#include <stdio.h>
#include <iostream>
int main(){
int dev = 0;
cudaDeviceProp devProp;
cudaGetDeviceProperties(&devProp, dev);
std::cout << "使用GPU device " << dev << ": " << devProp.name << std::endl;
std::cout << "SM的数量:" << devProp.multiProcessorCount << std::endl;
int warpSize = devProp.warpSize;
std::cout << "Warp size: " << warpSize << std::endl;
std::cout << "每个线程块的共享内存大小:" << devProp.sharedMemPerBlock / 1024.0 << " KB" << std::endl;
std::cout << "每个线程块的最大线程数:" << devProp.maxThreadsPerBlock << std::endl;
std::cout << "每个SM的最大线程数:" << devProp.maxThreadsPerMultiProcessor << std::endl;
std::cout << "每个SM的最大block数:" << devProp.maxThreadsPerMultiProcessor / warpSize << std::endl;
std::cout << "每个SM的寄存器数量:" << devProp.regsPerMultiprocessor << std::endl;
}nvcc -o gpu_check gpu_check.cu -run执行指令得到以下信息:
使用GPU device 0: NVIDIA GeForce GTX 1080 Ti
SM的数量:28
Warp size: 32
每个线程块的共享内存大小:48 KB
每个线程块的最大线程数:1024
每个SM的最大线程数:2048
每个SM的最大block数:64
每个SM的寄存器数量:65536
下面举一个简单的例子来说明如果根据硬件配置合理分配资源,假设一个SM上有8192个寄存器,程序员每个block设置了256个线程。
假设每个线程会占用10个寄存器,那么一个block中的线程会占用256*10=2560个寄存器,8192/2560=3.2,即一个SM可以同时加载3个block正常运行。
假设每个线程会占用11个寄存器,那么一个block中的线程会占用256*11=2816个寄存器,8192/2816=2.9,即一个SM只能加载2个block,一个SM上硬件资源就跑不满,会造成资源浪费。

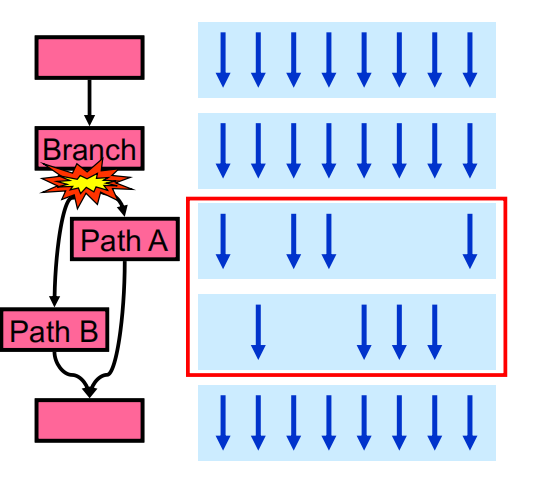
由于GPU没有复杂的控制单元,在warp中所有线程都会执行相同的指令,这意味着在遇到分支时,warp需要一些特殊的处理。如下图所示,当遇到分支时,warp中32个线程也许有些线程满足条件,有些线程不满足条件,但一个warp中所有线程执行指令的时序是一致的,不满足分支条件的线程必须等待需要执行指令的其他线程,这也意味着分支指令会影响GPU的运行效率,在程序设计时应该尽量少用,或者在写分支条件时尽可能保证一个warp中所有线程同时满足条件或者同时不满足条件。
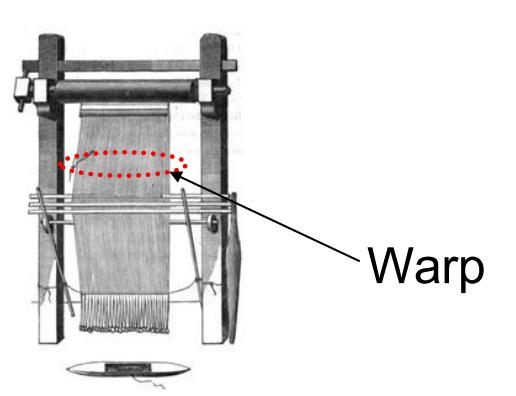
最后提一嘴,warp为什么叫warp?warp的英文意思有”编织物的纱线”,我们看下面这张图,假如说一个thread就是一条线,warp则是在机器上并发处理的很多条线。
CUDA编程实战
Which Thread?
CUDA程序中提供了 blockIdx, threadIdx, blockDim, GridDim来定位发起thread,下面我们发起1个grid,里面有2个block,每个block里有5个threads。
程序让每个thread输出自己的id号。
#include<stdio.h>
__global__ void print_id()
{
int id = blockIdx.x * blockDim.x + threadIdx.x;
printf("This is thread %d\n", id);
}
int main() {
print_id<<<2, 5>>>();
cudaDeviceSynchronize();
}Vector ADD
下面我们将向量a与向量b逐元素相加,计算的结果为向量c。使用cpu与GPU分别实现向量相加,并比较执行速度。
这里用到了”cudastart.h”定义了计算时间和初始化的函数:
#ifndef CUDASTART_H
#define CUDASTART_H
#define CHECK(call)\
{\
const cudaError_t error=call;\
if(error!=cudaSuccess)\
{\
printf("ERROR: %s:%d,",__FILE__,__LINE__);\
printf("code:%d,reason:%s\n",error,cudaGetErrorString(error));\
exit(1);\
}\
}
#include <time.h>
#ifdef _WIN32
# include <windows.h>
#else
# include <sys/time.h>
#endif
double cpuSecond()
{
struct timeval tp;
gettimeofday(&tp,NULL);
return((double)tp.tv_sec+(double)tp.tv_usec*1e-6);
}
void initialData(float* ip,int size)
{
time_t t;
srand((unsigned )time(&t));
for(int i=0;i<size;i++)
{
ip[i]=(float)(rand()&0xffff)/1000.0f;
}
}
void initialData_int(int* ip, int size)
{
time_t t;
srand((unsigned)time(&t));
for (int i = 0; i<size; i++)
{
ip[i] = int(rand()&0xff);
}
}
void initDevice(int devNum)
{
int dev = devNum;
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp,dev));
printf("Using device %d: %s\n",dev,deviceProp.name);
CHECK(cudaSetDevice(dev));
}
void checkResult(float * hostRef,float * gpuRef,const int N)
{
double epsilon=1.0E-8;
for(int i=0;i<N;i++)
{
if(abs(hostRef[i]-gpuRef[i])>epsilon)
{
printf("Results don\'t match!\n");
printf("%f(hostRef[%d] )!= %f(gpuRef[%d])\n",hostRef[i],i,gpuRef[i],i);
return;
}
}
printf("Check result success!\n");
}
#endifvector_add_gpu.cu
#include <stdio.h>
#include <assert.h>
#include <time.h>
#include "cudastart.h"
const int N = 1 << 28;
inline cudaError_t checkCuda(cudaError_t result)
{
if (result != cudaSuccess) {
fprintf(stderr, "CUDA Runtime Error: %s\n", cudaGetErrorString(result));
assert(result == cudaSuccess);
}
return result;
}
void initWith(int *a)
{
for(int i = 0; i < N; ++i)
{
a[i] = i;
}
}
__global__ void addVectorsInto(int *result, int *a, int *b)
{
int index = threadIdx.x + blockIdx.x * blockDim.x;
int gridstride = gridDim.x * blockDim.x;
for (int i = index; i < N; i += gridstride)
result[i] = a[i] + b[i];
}
void checkElementsAre(int *array)
{
for(int i = 0; i < N; i++)
{
if(array[i] != 2 * i)
{
printf("FAIL: array[%d] - %d does not equal %d\n", i, array[i], 2 * i);
exit(1);
}
}
printf("SUCCESS! All values added correctly.\n");
}
void cpuAdd(int *h_a, int *h_b, int *h_c){
int tid = 0;
while (tid < N) {
h_c[tid] = h_a[tid] + h_b[tid];
tid += 1;
}
}
int main()
{
size_t size = N * sizeof(int);
int *cpu_a = (int *)malloc(size);
int *cpu_b = (int *)malloc(size);
int *cpu_c = (int *)malloc(size);
initWith(cpu_a);
initWith(cpu_b);
double start_cpu = cpuSecond();
cpuAdd(cpu_a, cpu_b, cpu_c);
double end_cpu = cpuSecond();
checkElementsAre(cpu_c);
printf("vector add, CPU Time used: %f ms\n", (end_cpu - start_cpu) * 1000);
free(cpu_a);
free(cpu_b);
free(cpu_c);
int *a;
int *b;
int *c;
int deviceId;
cudaGetDevice(&deviceId);
checkCuda(cudaMallocManaged(&a, size));
checkCuda(cudaMallocManaged(&b, size));
checkCuda(cudaMallocManaged(&c, size));
cudaMemPrefetchAsync(a, size, cudaCpuDeviceId);
cudaMemPrefetchAsync(b, size, cudaCpuDeviceId);
initWith(a);
initWith(b);
cudaMemPrefetchAsync(a, size, deviceId);
cudaMemPrefetchAsync(b, size, deviceId);
size_t threadsPerBlock = 256;
size_t numberOfBlock = (N + threadsPerBlock - 1) / threadsPerBlock;
double start = cpuSecond();
addVectorsInto<<<numberOfBlock, threadsPerBlock>>>(c, a, b);
checkCuda(cudaDeviceSynchronize());
double end = cpuSecond();
checkElementsAre(c);
// Calculate elapsed time
printf("vector add, GPU Time used: %f ms\n", (end - start) * 1000);
cudaFree(a);
cudaFree(b);
cudaFree(c);
}这段代码需要向GPU申请显存,用以存储数组。
cudaMallocManaged 和 cudaMalloc 都是 CUDA 中用于分配设备内存的函数,它们之间有几个重要的区别:
- 管理方式:
cudaMallocManaged分配的内存是统一内存 (Unified Memory),可由 CPU 和 GPU 共享,无需显式地进行数据传输。这使得程序员可以更轻松地编写并行代码,而不必担心内存管理和数据传输。cudaMalloc分配的内存则是显式地分配给 GPU 使用的内存,需要通过显式的数据传输函数(如cudaMemcpy)来在 CPU 和 GPU 之间传输数据。
- 自动数据迁移:
- 统一内存由 CUDA 运行时自动管理数据的迁移。当 CPU 或 GPU 尝试访问未分配到当前设备的统一内存时,CUDA 运行时会自动将数据迁移到访问的设备上。
- 对于
cudaMalloc分配的内存,需要手动使用cudaMemcpy等函数进行数据传输。
- 便利性:
- 使用
cudaMallocManaged更加方便,因为无需手动管理数据的迁移和分配,程序员可以更专注于算法和逻辑的实现。 cudaMalloc则需要更多的手动管理,包括数据传输和内存释放。
- 使用
优缺点:
cudaMallocManaged的优点在于简化了内存管理和数据传输,提高了编程的便利性和代码的可读性。同时,由于统一内存的存在,可以减少内存使用上的一些烦琐问题。cudaMalloc的优点在于更加灵活,程序员可以精确地控制内存的分配和数据传输,适用于需要更细粒度控制的情况。此外,对于某些特定的算法和应用场景,手动管理内存和数据传输可能会比统一内存更加高效。
综上所述,选择使用 cudaMallocManaged 还是 cudaMalloc 取决于具体的应用场景和需求。
Reduction
对数组进行归约操作。
#include <cuda_runtime.h>
#include <stdio.h>
#include "cudastart.h"
__global__ void reduce_test(int *g_idata, int *sum, unsigned int n)
{
int idx = blockIdx.x*blockDim.x + threadIdx.x;
if (idx < n){
atomicAdd(sum, g_idata[idx]);
// sum[0] += g_idata[idx];
}
}
__global__ void reduceNeighbored(int * g_idata,int * g_odata,unsigned int n)
{
//set thread ID
unsigned int tid = threadIdx.x;
//boundary check
if (tid >= n) return;
//convert global data pointer to the
int *idata = g_idata + blockIdx.x*blockDim.x;
//in-place reduction in global memory
for (int stride = 1; stride < blockDim.x; stride *= 2)
{
if ((tid % (2 * stride)) == 0)
{
idata[tid] += idata[tid + stride];
}
//synchronize within block
__syncthreads();
}
//write result for this block to global mem
if (tid == 0)
g_odata[blockIdx.x] = idata[0];
}
__global__ void reduceNeighboredLess(int * g_idata,int *g_odata,unsigned int n)
{
unsigned int tid = threadIdx.x;
unsigned idx = blockIdx.x*blockDim.x + threadIdx.x;
// convert global data pointer to the local point of this block
int *idata = g_idata + blockIdx.x*blockDim.x;
if (idx > n)
return;
//in-place reduction in global memory
for (int stride = 1; stride < blockDim.x; stride *= 2)
{
//convert tid into local array index
int index = 2 * stride *tid;
if (index < blockDim.x)
{
idata[index] += idata[index + stride];
}
__syncthreads();
}
//write result for this block to global men
if (tid == 0)
g_odata[blockIdx.x] = idata[0];
}
__global__ void reduceInterleaved(int * g_idata, int *g_odata, unsigned int n)
{
unsigned int tid = threadIdx.x;
unsigned idx = blockIdx.x*blockDim.x + threadIdx.x;
// convert global data pointer to the local point of this block
int *idata = g_idata + blockIdx.x*blockDim.x;
if (idx >= n)
return;
//in-place reduction in global memory
for (int stride = blockDim.x/2; stride >0; stride >>=1)
{
if (tid <stride)
{
idata[tid] += idata[tid + stride];
}
__syncthreads();
}
//write result for this block to global men
if (tid == 0)
g_odata[blockIdx.x] = idata[0];
}
__global__ void reduceInterleaved_share(int * g_idata, int *g_odata, unsigned int n)
{
__shared__ int sh_arr[1024];
unsigned int tid = threadIdx.x;
unsigned idx = blockIdx.x*blockDim.x + threadIdx.x;
if (idx >= n)
return;
sh_arr[tid] = g_idata[idx];
__syncthreads();
//in-place reduction in global memory
for (int stride = blockDim.x/2; stride >0; stride >>=1)
{
if (tid <stride)
{
sh_arr[tid] += sh_arr[tid + stride];
}
__syncthreads();
}
//write result for this block to global men
if (tid == 0)
g_odata[blockIdx.x] = sh_arr[0];
}
int main(int argc,char** argv)
{
initDevice(0);
//initialization
int size = 1 << 24;
// printf(" with array size %d ", size);
//execution configuration
int blocksize = 1024;
if (argc > 1)
{
blocksize = atoi(argv[1]); //从命令行输入设置block大小
}
dim3 block(blocksize, 1);
dim3 grid((size - 1) / block.x + 1, 1);
printf("grid %d block %d \n", grid.x, block.x);
//allocate host memory
size_t bytes = size * sizeof(int);
int *idata_host = (int*)malloc(bytes);
int *odata_host = (int*)malloc(grid.x * sizeof(int));
int * tmp = (int*)malloc(bytes);
//initialize the array
initialData_int(idata_host, size);
if (size < 100)
{
printf("Array: [");
for (int i = 0; i < size; ++i)
printf("%d, ", idata_host[i]);
printf("]\n");
}
memcpy(tmp, idata_host, bytes);
double timeStart, timeElaps;
int gpu_sum = 0;
// device memory
int * idata_dev = NULL;
int * odata_dev = NULL;
CHECK(cudaMalloc((void**)&idata_dev, bytes));
CHECK(cudaMalloc((void**)&odata_dev, grid.x * sizeof(int)));
//cpu reduction 对照组
int cpu_sum = 0;
timeStart = cpuSecond();
for (int i = 0; i < size; i++)
cpu_sum += tmp[i];
timeElaps = 1000*(cpuSecond() - timeStart);
printf("cpu sum:%d \n", cpu_sum);
printf("cpu reduction elapsed %lf ms cpu_sum: %d\n", timeElaps, cpu_sum);
//kernel 0 reduce
int *reduce_sum;
CHECK(cudaMalloc((void**)&reduce_sum, sizeof(int)));
CHECK(cudaMemset(reduce_sum, 0, sizeof(int)));
CHECK(cudaMemcpy(idata_dev, idata_host, bytes, cudaMemcpyHostToDevice));
cudaDeviceSynchronize();
timeStart = cpuSecond();
reduce_test <<<grid, block >>>(idata_dev, reduce_sum, size);
cudaDeviceSynchronize();
cudaMemcpy(&gpu_sum, reduce_sum, sizeof(int), cudaMemcpyDeviceToHost);
printf("gpu sum:%d \n", gpu_sum);
printf("gpu atomicAdd elapsed %lf ms <<<grid %d block %d>>>\n",
timeElaps, grid.x, block.x);
CHECK(cudaFree(reduce_sum));
//kernel 1 reduceNeighbored
CHECK(cudaMemcpy(idata_dev, idata_host, bytes, cudaMemcpyHostToDevice));
CHECK(cudaDeviceSynchronize());
timeStart = cpuSecond();
reduceNeighbored <<<grid, block >>>(idata_dev, odata_dev, size);
cudaDeviceSynchronize();
cudaMemcpy(odata_host, odata_dev, grid.x * sizeof(int), cudaMemcpyDeviceToHost);
gpu_sum = 0;
for (int i = 0; i < grid.x; i++)
gpu_sum += odata_host[i];
timeElaps = 1000*(cpuSecond() - timeStart);
printf("gpu sum:%d \n", gpu_sum);
printf("gpu reduceNeighbored elapsed %lf ms <<<grid %d block %d>>>\n",
timeElaps, grid.x, block.x);
//kernel 2 reduceNeighboredless
CHECK(cudaMemcpy(idata_dev, idata_host, bytes, cudaMemcpyHostToDevice));
CHECK(cudaDeviceSynchronize());
timeStart = cpuSecond();
reduceNeighboredLess <<<grid, block >>>(idata_dev, odata_dev, size);
cudaDeviceSynchronize();
cudaMemcpy(odata_host, odata_dev, grid.x * sizeof(int), cudaMemcpyDeviceToHost);
gpu_sum = 0;
for (int i = 0; i < grid.x; i++)
gpu_sum += odata_host[i];
timeElaps = 1000*(cpuSecond() - timeStart);
printf("gpu sum:%d \n", gpu_sum);
printf("gpu reduceNeighboredless elapsed %lf ms <<<grid %d block %d>>>\n",
timeElaps, grid.x, block.x);
//kernel 3 reduceInterleaved
CHECK(cudaMemcpy(idata_dev, idata_host, bytes, cudaMemcpyHostToDevice));
CHECK(cudaDeviceSynchronize());
timeStart = cpuSecond();
reduceInterleaved <<<grid, block >>>(idata_dev, odata_dev, size);
cudaDeviceSynchronize();
cudaMemcpy(odata_host, odata_dev, grid.x * sizeof(int), cudaMemcpyDeviceToHost);
gpu_sum = 0;
for (int i = 0; i < grid.x; i++)
gpu_sum += odata_host[i];
timeElaps = 1000*(cpuSecond() - timeStart);
printf("gpu sum:%d \n", gpu_sum);
printf("gpu reduceInterleaved elapsed %lf ms <<<grid %d block %d>>>\n",
timeElaps, grid.x, block.x);
//kernel 4 reduceInterleaved shared memory
CHECK(cudaMemcpy(idata_dev, idata_host, bytes, cudaMemcpyHostToDevice));
CHECK(cudaDeviceSynchronize());
timeStart = cpuSecond();
reduceInterleaved_share <<<grid, block >>>(idata_dev, odata_dev, size);
cudaDeviceSynchronize();
cudaMemcpy(odata_host, odata_dev, grid.x * sizeof(int), cudaMemcpyDeviceToHost);
gpu_sum = 0;
for (int i = 0; i < grid.x; i++)
gpu_sum += odata_host[i];
timeElaps = 1000*(cpuSecond() - timeStart);
printf("gpu sum:%d \n", gpu_sum);
printf("gpu reduceInterleaved elapsed %lf ms <<<grid %d block %d>>>\n",
timeElaps, grid.x, block.x);
// free host memory
free(idata_host);
free(odata_host);
CHECK(cudaFree(idata_dev));
CHECK(cudaFree(odata_dev));
//reset device
cudaDeviceReset();
//check the results
if (gpu_sum == cpu_sum)
{
printf("Test success!\n");
}
return EXIT_SUCCESS;
}Matrix multiplication
计算二维矩阵乘法。
#include <cuda_runtime.h>
#include <stdio.h>
#include "cudastart.h"
#define N 1024
#define tile_size 16
void matrixMulCPU( int * a, int * b, int * c )
{
int val = 0;
for( int row = 0; row < N; ++row )
for( int col = 0; col < N; ++col )
{
val = 0;
for ( int k = 0; k < N; ++k )
val += a[row * N + k] * b[k * N + col];
c[row * N + col] = val;
}
}
__global__ void matrixMulGPU( int * a, int * b, int * c )
{
int row = blockIdx.x * blockDim.x + threadIdx.x;
int col = blockIdx.y * blockDim.y + threadIdx.y;
int val = 0;
for(int i = 0; i < N; ++i){
val += a[row * N + i] * b[i * N + col];
}
c[row * N + col] = val;
}
__global__ void matrixGPU_tile( int * a, int * b, int * c )
{
__shared__ int tile_a[tile_size][tile_size];
__shared__ int tile_b[tile_size][tile_size];
int row = blockIdx.x * blockDim.x + threadIdx.x;
int col = blockIdx.y * blockDim.y + threadIdx.y;
for (int i = 0; i < N / tile_size; ++i){
tile_a[threadIdx.x][threadIdx.y] = a[row * N + i * tile_size + threadIdx.y];
tile_b[threadIdx.x][threadIdx.y] = b[(i * tile_size + threadIdx.x) * N + col];
__syncthreads();
for (int j = 0; j < tile_size; ++j){
c[row * N + col] += tile_a[threadIdx.x][j] * tile_b[j][threadIdx.y];
}
__syncthreads();
}
}
void check(int *c_cpu, int *c_gpu){
bool error = false;
for( int row = 0; row < N && !error; ++row )
for( int col = 0; col < N && !error; ++col ){
if (c_cpu[row * N + col] != c_gpu[row * N + col])
{
printf("FOUND ERROR at c[%d][%d]\n", row, col);
error = true;
break;
}
}
if (!error)
printf("Success!\n");
}
int main()
{
int *a, *b, *c_cpu, *c_gpu, *c_gpu_opt; // Allocate a solution matrix for both the CPU and the GPU operations
int size = N * N * sizeof (int); // Number of bytes of an N x N matrix
double timeStart, timeElaps;
// Allocate memory
cudaMallocManaged (&a, size);
cudaMallocManaged (&b, size);
cudaMallocManaged (&c_cpu, size);
cudaMallocManaged (&c_gpu, size);
cudaMallocManaged (&c_gpu_opt, size);
initialData_int(a, N * N);
initialData_int(b, N * N);
memset(c_cpu, 0, N * N);
memset(c_gpu, 0, N * N);
memset(c_gpu_opt, 0, N * N);
timeStart = cpuSecond();
matrixMulCPU( a, b, c_cpu );
timeElaps = 1000 * (cpuSecond() - timeStart);
printf("cpu matrix mul time: %f ms\n", timeElaps);
// test kernel 1: matrixMulGPU
dim3 threads_per_block(16, 16, 1);
dim3 number_of_blocks(N / threads_per_block.x, N / threads_per_block.y, 1);
timeStart = cpuSecond();
matrixMulGPU <<< number_of_blocks, threads_per_block >>> ( a, b, c_gpu );
timeElaps = 1000 * (cpuSecond() - timeStart);
cudaDeviceSynchronize();
printf("gpu matrix mul time: %f ms\n", timeElaps);
check(c_cpu, c_gpu);
// test kernel 2: matrixMulGPU optimize
timeStart = cpuSecond();
matrixGPU_tile <<< number_of_blocks, threads_per_block >>> ( a, b, c_gpu_opt );
timeElaps = 1000 * (cpuSecond() - timeStart);
cudaDeviceSynchronize();
printf("gpu matrix mul time: %f ms\n", timeElaps);
check(c_cpu, c_gpu_opt);
// Free all our allocated memory
cudaFree(a); cudaFree(b);
cudaFree( c_cpu ); cudaFree( c_gpu ); cudaFree( c_gpu_opt );
}
CUDNN
使用cuDNN实现sigmoid函数
#include <iostream>
#include <cuda_runtime.h>
#include <cudnn.h>
/**
* Minimal example to apply sigmoid activation on a tensor
* using cuDNN.
* https://docs.nvidia.com/deeplearning/cudnn/latest/api/cudnn-graph-library.html#
* https://docs.nvidia.com/deeplearning/cudnn/latest/api/cudnn-ops-library.html#cudnnactivationforward
**/
int main(int argc, char** argv)
{
// get gpu info
int numGPUs;
cudaGetDeviceCount(&numGPUs);
std::cout << "Found " << numGPUs << " GPUs." << std::endl;
cudaSetDevice(0); // use GPU0
int device;
struct cudaDeviceProp devProp;
cudaGetDevice(&device);
cudaGetDeviceProperties(&devProp, device);
std::cout << "Compute capability:" << devProp.major << "." << devProp.minor << std::endl;
cudnnHandle_t handle_;
cudnnCreate(&handle_);
std::cout << "Created cuDNN handle" << std::endl;
// create the tensor descriptor
cudnnDataType_t dtype = CUDNN_DATA_FLOAT;
cudnnTensorFormat_t format = CUDNN_TENSOR_NCHW;
int n = 1, c = 1, h = 1, w = 10;
int NUM_ELEMENTS = n*c*h*w;
cudnnTensorDescriptor_t x_desc;
cudnnCreateTensorDescriptor(&x_desc);
cudnnSetTensor4dDescriptor(x_desc, format, dtype, n, c, h, w);
// create the tensor
float *x;
// 创建 Unified Memory,这样cpu和memory都可以使用
cudaMallocManaged(&x, NUM_ELEMENTS * sizeof(float));
for(int i=0;i<NUM_ELEMENTS;i++) x[i] = i * 1.00f;
std::cout << "Original array: ";
for(int i=0;i<NUM_ELEMENTS;i++) std::cout << x[i] << " ";
// create activation function descriptor
float alpha[1] = {1};
float beta[1] = {0.0};
cudnnActivationDescriptor_t sigmoid_activation;
cudnnActivationMode_t mode = CUDNN_ACTIVATION_SIGMOID;
cudnnNanPropagation_t prop = CUDNN_NOT_PROPAGATE_NAN;
cudnnCreateActivationDescriptor(&sigmoid_activation);
cudnnSetActivationDescriptor(sigmoid_activation, mode, prop, 0.0f);
cudnnActivationForward(
handle_,
sigmoid_activation,
alpha,
x_desc,
x,
beta,
x_desc,
x
);
cudnnDestroy(handle_);
std::cout << std::endl << "Destroyed cuDNN handle." << std::endl;
std::cout << "New array: ";
for(int i=0;i<NUM_ELEMENTS;i++) std::cout << x[i] << " ";
std::cout << std::endl;
cudaFree(x);
return 0;
}cuDNN文档: https://docs.nvidia.com/deeplearning/cudnn/latest/api/cudnn-graph-library.html
参考资料
CUDA编程入门(五)更高效的并行归约算法 - ZihaoZhao的文章 - 知乎
理解CUDA中的thread,block,grid和warp - 三七和酒的文章 - 知乎
《分布式与并行计算技术》 刘莹
《计算机体系结构》 张科 刘珂 高婉铃

